打造可商用的Java程序之可维护性
在主函数中捕获未处理的异常#
在主函数中捕获未处理的异常,防止程序崩溃,同时记录日志,方便排查问题。
1 | public class UncaughtExceptionHandle { |
在主函数中捕获未处理的异常,防止程序崩溃,同时记录日志,方便排查问题。
1 | public class UncaughtExceptionHandle { |
记一次中文指标乱码问题,问题也很简单,如下图所示:
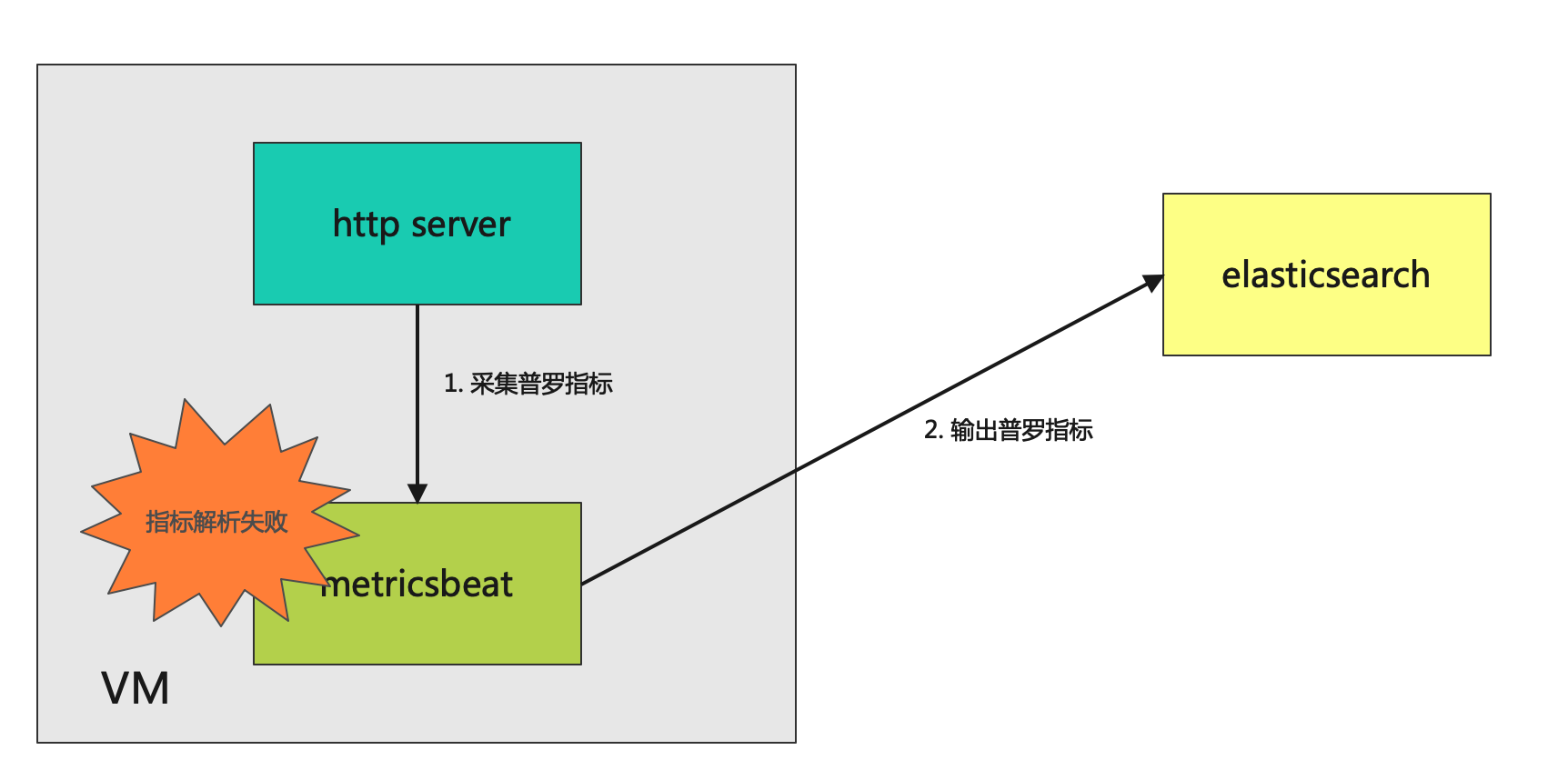
从metricbeat开始找原因,发现其实只要是UTF-8的编码格式就都可以解析,最终发现是webServer返回的数据非UTF-8格式,修改方案也很简单。将servlet中的content-type里面的text/plain修改成text/plain; charset=utf-8就可以了,如下面代码所示:
1 | protected void doGet(HttpServletRequest request, HttpServletResponse response) |
我们可以轻易使用一个demo来复现这个问题,在maven中添加如下依赖
1 | <dependency> |
1 | package com.shoothzj.jetty; |
通过curl命令来复现这个问题
1 | curl localhost:8080/hello-default |
那么servlet里面的数据如何编码,我们可以dive一下,首先servlet里面有一个函数叫**response.setCharacterEncoding();**这个函数可以指定编码格式。其次,servlet还会通过上面的setContentType函数来做一定的推断,比如content-type中携带了charset,就使用content-type中的charset。还有些特定的content-type,比如text/json,在没有设置的情况下,servlet容器会假设它使用utf-8编码。在推断不出来,也没有手动设置的情况下,jetty默认的编码是iso-8859-1,这就解释了乱码的问题。
微服务广播模式,指的是在微服务多实例部署的场景下,将消息广播到多个微服务实例的一种模式。
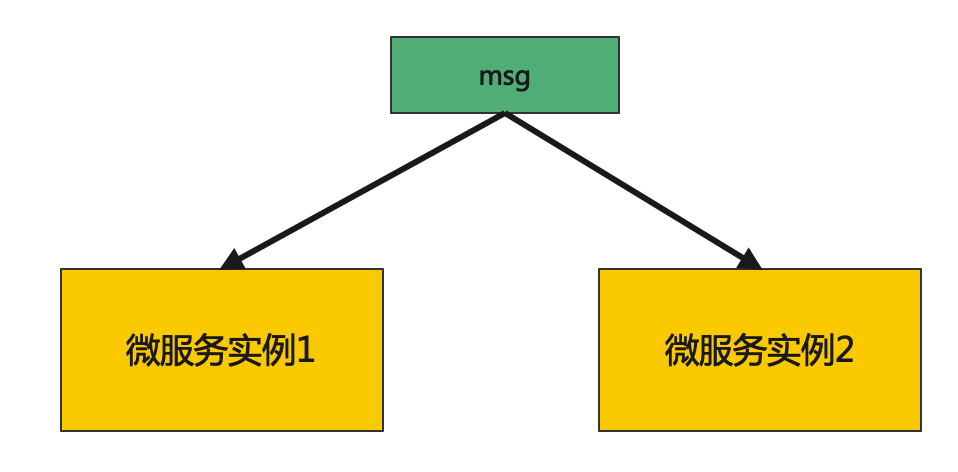
广播模式,一般用来维护微服务的内存数据,根据数据类型的不同,有助于解决两类问题。通常广播模式会使用支持发布订阅的消息中间件实现(如Redis、Kafka、Pulsar等),本文也基于消息中间件进行讨论。
这应该是广播模式利用最多的一种场景,假想一个拥有海量用户的电商网站、或是一个亿级设备连接的IoT平台。势必会存在一些缓存数据,像是用户的购物车信息,或是设备的密钥缓存。如果没有广播模式,可能会存在这样的问题
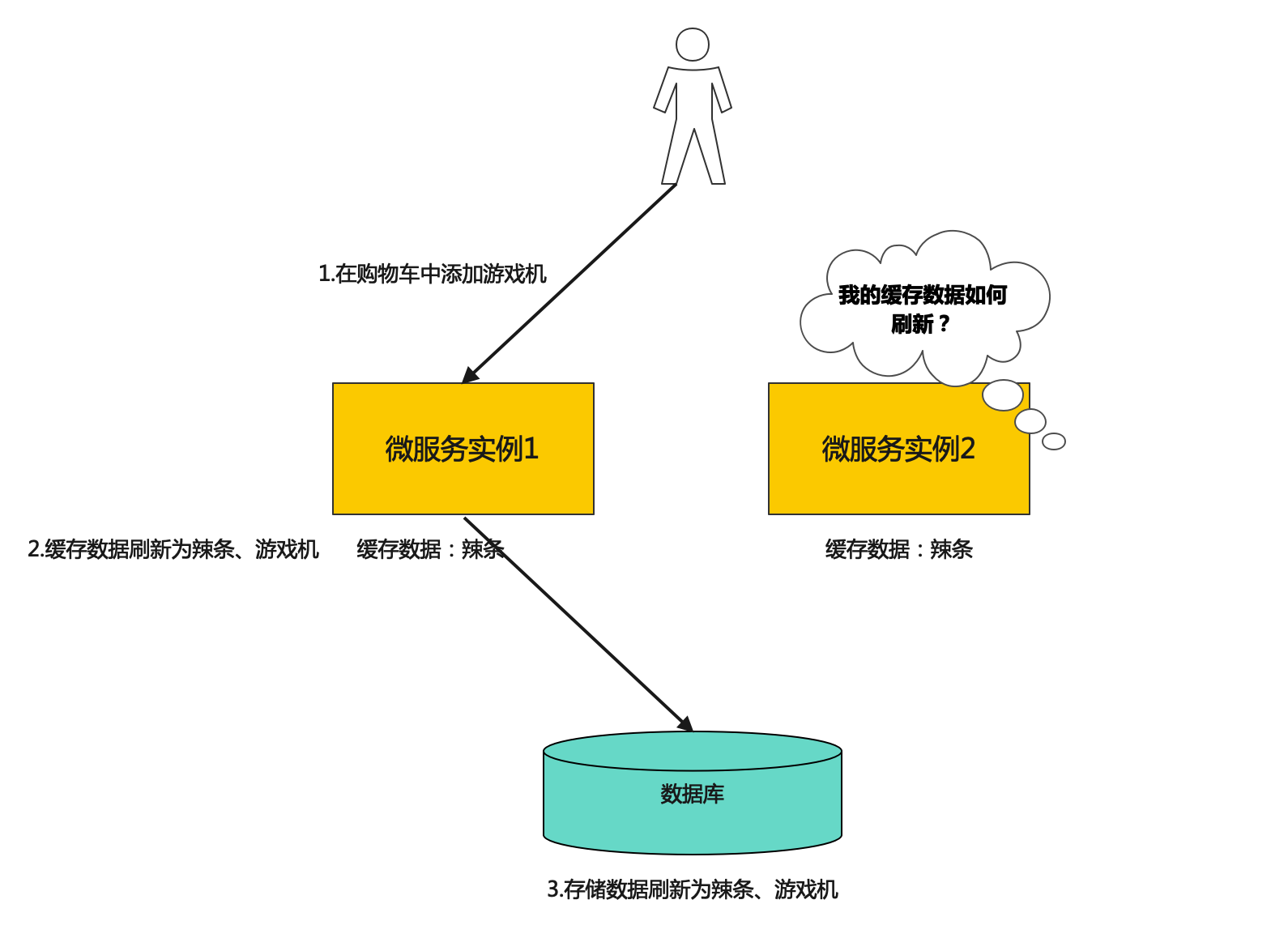
当用户更新了它的购物车之后,微服务实例1的数据发生了更新,数据库的数据也成功更新。但是微服务实例2中的缓存数据未能更新,那么如果用户的请求均衡到了实例2,就会发生意想不到的后果。
这种情况下我们可以让微服务1在广播通道中发送一个缓存的invalidate消息,将微服务实例2中该用户的缓存清零,使得微服务实例2在下一次处理该用户的请求时,从数据库中读取最新的消息。
使用该模式需要注意的点:
为什么说消费组老化比较重要呢,因为很多监控系统都会根据消费组的积压来做告警,很容易产生误告警。
这种模式相对比较少见,常见于key的基数不是很大,能够将数据完整地存储在内存中,比如电商平台的企业卖家个数、物联网平台的用户个数等,并且对数据的一致性要求不是很高(因为广播模式情况下,对于两个微服务实例来说没有一致性保障)。像Apache Pulsar设计的TableView,在我看来,就是做这个事的一个最佳实践。Pulsar内部大量使用了topic存储数据,就是采用这个方式。
使用该模式需要注意的点:
因为在极端场景下,无论是graceful的代码,还是监听kill信号的代码,都不能保证代码百分百地被执行。需要兜底。
Kafka通过offsets.retention.minutes参数控制消费组中offsets保留时间,在此时间内如果没有提交offset,offsets将会被删除。Kafka判定消息组中没有在线的消费者(如empty状态),且没有offsets时,将会删除此消费组。
pulsar的消费组老化策略更加灵活,可以配置到namespace级别。
1 | bin/pulsar-admin namespaces | grep expiration |
这里注意要合理地配置消费组的老化时间,在pulsar的当前版本(2.11版本)下,catch up读,也就是说消费组平时积压量不大。如果将消费组的老化时间配置大于等于消息的老化时间,会出现消费组老化不了的现象。
当然,由于消费组和消息老化都是定时任务,预估时间时,要考虑一定的buffer。
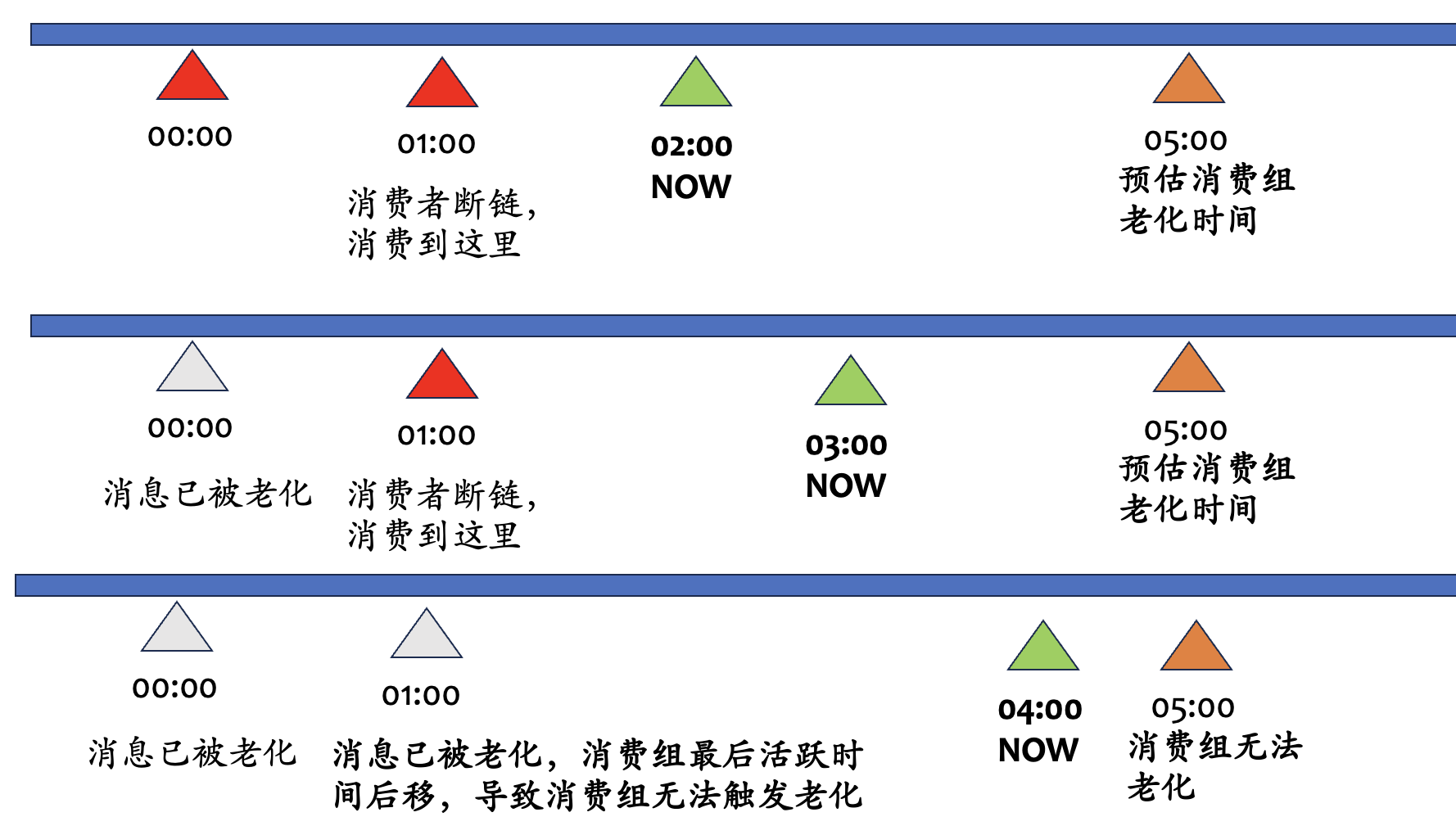
这里让我们稍稍dive一下原理,消费组的老化是通过判断Cursor游标的LastActive time来判断能否老化的。如果该消费组的游标位置到达了消息老化区域,被老化掉了,消费组的游标位置就会强制更新到一个可用的位置,这个时候会更新游标的LastActive time到当前时间,周而复始,导致消费组无法老化。举个🌰
假设消费组的老化时间为4h,消息的老化时间为3h,就可能会发生这样的事情
广播模式在微服务架构中起到了重要的角色,尤其是在需要在微服务实例之间同步数据的场景中,它具有显著的优势。它能够帮助维护内存数据的缓存一致性。希望本篇文章能提供您全面的广播模式的知识。
近期,我再次涉足于协议服务器相关的工作领域,致力于定位并解决各种问题。简单总结一些心得给大家。如果想要定位出协议服务器的问题,那么这些能力可能至关重要。
注:我这里比较偏向协议本身的问题,不涉及一些通用的网络问题(如网络吞吐量上不去、响应时间长等等)
首先,网络协议服务器本质上也是一个应用程序。因此,需要具备一些关于CPU和内存的通用分析能力。PU/内存火焰图,内存dump分析,锁分析,以及远程调试(研发态手段)这些手段都要具备
为了有效地定位网络问题,日志需要精确到毫秒级别。没有毫秒级别的精度,定位网络问题就会变得极其困难。所以golang的logrus默认只有秒级别,我觉得不太好,用rfc3339就很好。
在打印日志时,我们不能太过随意。例如,“connection lost”这样的日志,在调试阶段可能看似无大碍,但当真正的业务量和连接数大幅增加时,这种模糊的日志信息就会让人束手无策。
理想的日志至少应包含网络地址信息,这样我们可以根据网络地址和时间点来查阅日志。如果有抓包的话,那就更好了,可以从中获取大量信息。
当然,我们并不需要在所有的日志中都包含网络地址信息。例如,一旦完成了用户身份的鉴定,我们就可以打印用户的身份信息,这样更方便与后续的业务流程进行整合。如果需要查询网络地址信息,可以回溯到建立连接时的日志。举个🌰
1 | 2023-05-30 23:59:01.000 [INFO] 127.0.0.1:62345 connected |
假设一条数据链上有大量的消息呢?在现代的网络环境中,一条TCP链接可以轻易达到5M bit/s以上的数据流。即使我们提供了时间点信息,仍然很难找到具有问题的报文(在同一秒内可能有上千条报文)。在这种情况下,就需要引入会话的ID信息。许多TCP协议会携带这种信息,换句话说,支持IO复用的协议都会有这种信息(比如MQTT的messageId,Kafka的correlationId等)。此类信息应该被正确地打印在日志中。
你可能已经在调试日志中包含了非常详尽的信息,然而在实际环境中,这可能并没有太大用处。
原因是一旦全面开启debug日志,性能消耗会大幅增加。除非你的系统性能冗余极大,否则根本无法正常运行。
为此,我们可以提升debug的能力,针对特定的特征值开启debug,例如网络地址、mqtt的clientId、消息中间件的topic等。应用程序仅针对这些特征值打印详细的日志,这样的开销就相对较小,而且这种方法已经在生产环境中被我多次验证。
在网络协议服务器中,我们需要将网络报文与业务trace关联起来。这种关联能力的实现可以大大提高我们定位业务端到端问题的效率和准确性。 理想情况下,我们应该能够根据网络报文来查找相关的业务trace,反之亦然,根据业务trace来查找对应的网络报文。但这些手段都需要业务端的配合,比如在报文中携带traceId,或者在业务trace中携带网络地址信息。
以mqtt协议为例,可以在payload中带上
1 | { |
在这个例子中,traceId就是我们为业务trace设定的唯一标识符,而data则是实际的业务数据。通过在网络报文中携带这些信息,我们就可以轻松地将网络报文与其对应的业务trace关联起来。
然而,这种方法在研发和测试环境中实现相对容易,但在生产环境中可能会遇到更多的困难。首先,对于在网络报文中携带traceId这一做法,业界并未形成统一的规范和实践。这导致在生产环境,极难做到。
更具挑战性的是,如果你面对的是一个端到端的复杂系统,将traceId从系统的入口传递到出口可能会遇到许多难以预见的问题。例如系统不支持这类数据的专递,这就封死了这条路。
查看原始报文的能力极其重要,特别是在协议栈的实现尚不成熟的情况下。如果无法查看原始报文,定位问题就会变得非常困难。我曾说过:“如果拿到了原始报文,还是无法复现问题,那我们的研发能力在哪里?”虽然这句话可能有些极端,但它准确地强调了抓包的重要性。
我们可以从抓包看出网络的连通性、网络的延迟、网络的吞吐量、报文的格式、报文的正确性等等。如果途径了多个网元,那么是谁的错?(一般来说,看抓包,谁先发RST,就从谁身上找原因)
虽然抓包的命令比较简单tcpdump port 8080 -i eth0 -s0 -w my.pcap就抓了,但实际想做成,最大的阻力是这两个,TLS和复杂的现网环境
在旧版本的TLS密钥交换算法下,只要有私钥和密码,就可以顺利解包,但现在的tls,都支持前向加密,什么叫前向加密呢?简单地来说,就是给你私钥和密码,你也解不出来。有tls debuginfo和ebpf能解决这两个问题,tls debug-info的原理是将密钥交换时的密钥输出持久化到某个地方,然后拿这个去解,实际很少见有人用这个方案。ebpf一需要linux内核高版本,同时还需要开启功能,安装kernel-debug-info,门槛也比较高。
现网环境,像抓包嗅探的这种工具,有时候可能是禁止上传的,或者即使能上传成功,也需要很长的时间。
也许我们可以通过“应用层抓包”来解决上述的问题,在网络层,我们支持受限的抓包能力,比如可以抓针对某个特征值(比如网络地址、messageId)的包,因为我们在应用层,可使用的过滤条件更多,更精细,输出到某个路径,这个报文的组装,完全在应用网络层,虽然看不到物理层的一些信息,但对于应用程序来说,除非我是做nat设备的,一般用不到这些信息。继续用这个报文来分析问题。实现应用层抓包,也要注意对内存的占用等等,不能因为这个功能,把整个进程搞崩溃。
在应用层抓包,第一步就是确定抓包的地点。由于我们是在应用层进行操作,因此抓包地点一般位于应用程序与网络协议栈的交接处。例如,你可以在数据包刚被应用接收,还未被处理之前进行抓包,或者在数据包即将被应用发送出去,还未进入网络协议栈之前进行抓包。
设定过滤条件是抓包的关键,因为在实际环境中,数据流量可能非常大,如果没有过滤条件,抓包的数据量可能会非常庞大,对应用和系统的性能产生影响。在应用层,我们可以设置更多更精细的过滤条件,如网络地址、端口、协议类型、特定的字段等。这些过滤条件可以帮助我们更精确地定位问题,减少无效的数据。
将抓到的数据存储起来也是很重要的一步。可以选择将数据存储到内存或者硬盘。需要注意的是,如果选择存储到内存,要考虑到内存的大小,避免因为抓包数据过大导致内存溢出。如果选择存储到硬盘,要考虑到硬盘的读写速度和容量,避免因为抓包数据过大导致硬盘满载。
本文首先阐述了网络协议服务器的一些问题定位能力,包括CPU内存分析能力、日志和网络连接的关联能力、针对特征值的跟踪能力,以及查看原始报文的能力,也讨论了将网络报文与业务trace有效关联的重要性和实现挑战。强调了抓包的重要性和对于解密TLS报文的挑战。为了解决网络层抓包遇到的困难,我们可以考虑应用层抓包方案。最后,我们讨论了应用层抓包的一些关键问题,包括抓包地点的选择、过滤条件的设定和数据存储问题。
Pulsar像大多数消息中间件一样,支持按时间和大小对消息积压进行老化。但是默认的策略只能在namespace级别配置。本文将介绍如何在topic级别实现老化策略的两种方案。
默认的策略配置通过在Zookeeper上配置对应的策略,可以通过./pulsar zookeeper-shell命令来登录zookeeper集群查询。但是如果将这一实现方式扩展到topic级别,将会产生大量的(百万、千万级别)的ZooKeeper节点,这对于ZooKeeper集群来说几乎是不可接受的。因此,Pulsar提供了一种新的实现方式,即通过Topic来存储策略配置,而不是通过ZooKeeper来存储。
Pulsar,从2.7.0版本开始,引入了SystemTopic,用于存储Topic的元数据信息,包括Topic的策略配置。主题级策略使用户可以更灵活地管理主题,并不会给 ZooKeeper 带来额外负担。
您可以通过如下配置来开启TopicLevelPolicy:
1 | systemTopicEnabled=true |
然后通过set-backlog-quota命令来设置您想要的老化时间和老化大小
PS: 完整的一些功能,如命令行set-backlog-quota,在3.0.0版本中支持
Pulsar的TopicLevelPolicy实现需要通过topic存储策略配置,而不是通过ZooKeeper来存储。在实际的极端场景下,Topic中存储的内容可能会丢失(因为未开启Bookkeeper立即落盘或磁盘文件损坏等原因),这将导致策略配置丢失,从而导致策略失效。因此,我们可以通过自定义代码来实现topic级别的策略配置,这样可以避免策略配置丢失的问题。
举个例子,业务可以将策略存放在Mysql中,然后通过Pulsar的Admin API来让策略生效
sequenceDiagram
participant C as Client
participant B as Broker
loop
C ->> B: expire-messages-all-subscriptions Request
B -->> C: expire-messages-all-subscriptions Response
end
sequenceDiagram
participant C as Client
participant B as Broker
loop
C ->> B: stats-internal Request
B -->> C: stats-internal Response
alt messageBacklogSize < maxMessageBacklogSize
else messageBacklogSize >= maxMessageBacklogSize
Note over B,C: estimate the backlog position
C ->> B: get-message-by-id Request
B -->> C: get-message-by-id
Note over B,C: get the timestamp of the message
C ->> B: expire-messages-all-subscriptions Request
B -->> C: expire-messages-all-subscriptions Response
end
end
你的mysql客户端和服务端之间开启tls了吗?你的回答可能是No,我没有申请证书,也没有开启mysql客户端,服务端的tls配置。
可是当你抓取了3306 mysql的端口之后,你会发现,抓出来的包里居然有Client Hello、Server Hello这样的典型TLS报文。
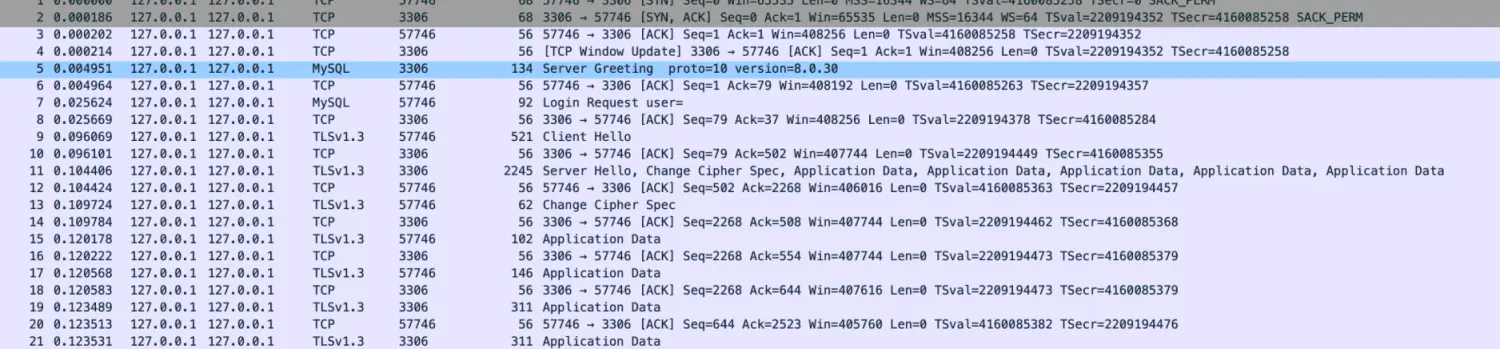
其实,Mysql的通信是否加密,是由客户端和服务端共同协商是否开启的,客户端与服务端都处于默认配置下的话,有些类似于StartTls。
在连接建立时,Mysql服务端会返回一个Server Greeting,其中包含了一些关于服务端的信息,比如协议版本、Mysql版本等等。在其中有一个flag的集合字段,名为
Capabilities Flag,顾名思义,这就是用来做兼容性,或者说特性开关的flag,大小为2个字节,其中的第12位,代表着CLIENT_SSL
,如果设置为1,那代表着如果客户端具备能力,服务端可以在后面的会话中切换到TLS。可以看到里面还有一些其他的flag,事务、长密码等等相关的兼容性开关。
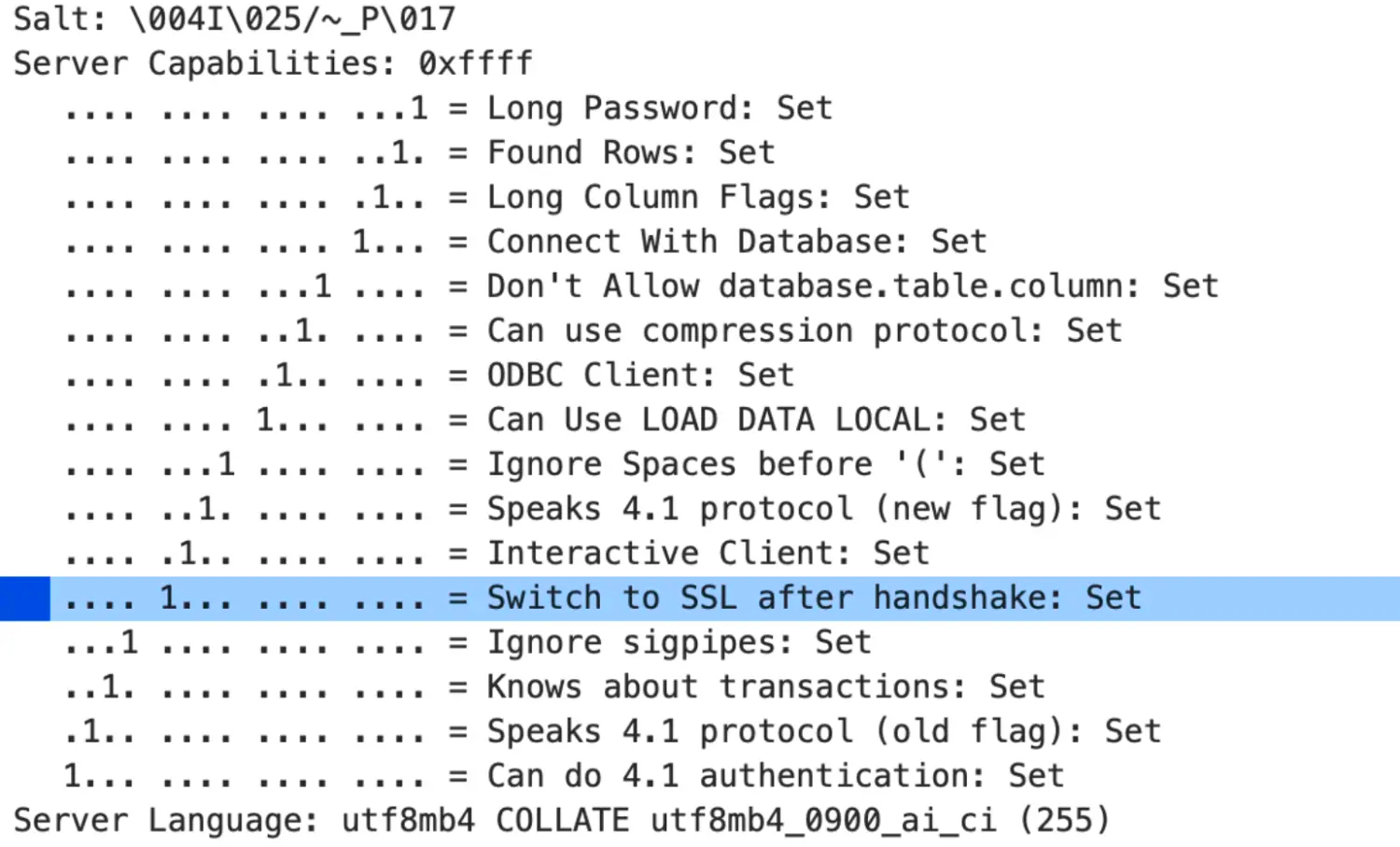
我们可以测试一下设置为0的行为,只需要在my.cnf中添加
1 | echo "ssl=0" >> /etc/my.cnf |
重启mysql。再度进行抓包,就发现没有tls的报文了,都是在使用明文进行通信了。
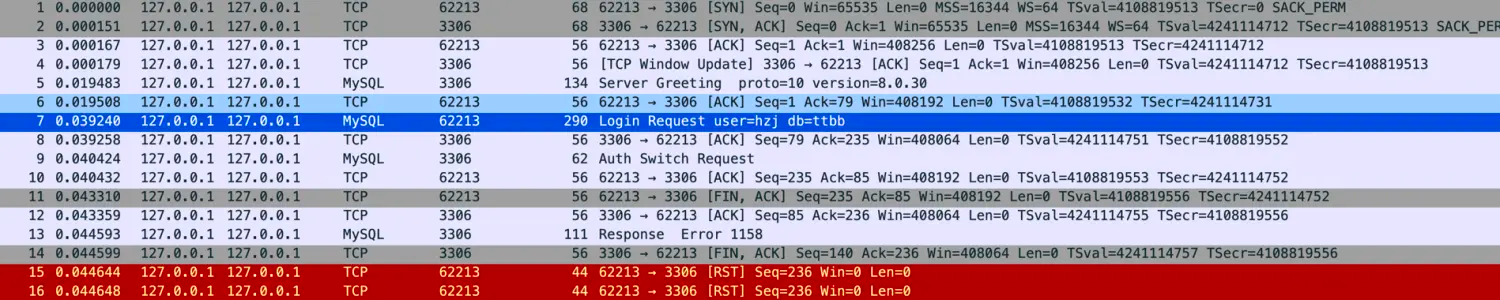
这个协商过程也可以在客户端进行控制,客户端对应的参数是sslMode,可以设置为DISABLED、PREFERRED、REQUIRED、VERIFY_CA、VERIFY_IDENTITY,分别代表不使用ssl、优先使用ssl、必须使用ssl、验证CA、验证身份。默认的行为是PREFERRED,example:
比如配置sslMode为DISABLED,那么客户端就不会使用ssl进行通信,而是使用明文。
1 | r2dbc:mysql://localhost:3306/test?sslMode=DISABLED |

| 客户端 | 服务端 | 结果 |
|---|---|---|
| DISABLED | ssl=0 | PLAIN |
| DISABLED | ssl=1 | PLAIN |
| PREFERRED | ssl=0 | PLAIN |
| PREFERRED | ssl=1 | TLS |
| REQUIRED | ssl=0 | Fail |
| REQUIRED | ssl=1 | TLS |
| VERIFY_CA | ssl=0 | Fail |
| VERIFY_CA | ssl=1 + CA配置 | TLS,客户端验证证书 |
| VERIFY_IDENTITY | ssl=0 | Fail |
| VERIFY_IDENTITY | ssl=1 + CA配置 | TLS,客户端验证证书和域名 |
注:
kubernetes中容器获取IP地址是一个常见的需求,常见的有两种获取IP地址的方式
通过在部署时,container下的env中配置如下yaml
1 | - name: POD_IP |
进入容器就可以根据环境变量获取到容器IP
1 | # echo $POD_IP |
1 | # ip addr show eth0 | grep "inet\b" | awk '{print $2}' | cut -d/ -f1 |
注意这里一定要用inet\b,不要用inet。使用inet的话,在Ipv6双栈场景下会因为匹配到inet6获取到错误的结果, Ipv6双栈场景下ip命令的部分输出结果如下图所示
1 | inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0 |
不推荐使用ifconfig命令的原因是,这个命令已经废弃,将会逐步删除
1 | ifconfig eth0 | grep 'inet\b' | awk '{print $2}' | cut -d/ -f1 |
同样需要使用inet\b,不要使用inet
优先配置如下yaml进行环境变量注入,其次使用ip addr show eth0 | grep “inet\b” | awk ‘{print $2}’ | cut -d/ -f1命令获取
1 | - name: POD_IP |
在一些场景下,您的kubernetes集群已经搭建完成了,但是还需要修改一些核心组件的参数,如etcd、kube-apiserver、kube-scheduler、kube-controller-manager等。
通过kubectl get pod -owide -n kube-system 可以查看到这些核心容器。
1 | NAME READY STATUS RESTARTS AGE |
以etcd为例,etcd的参数就在pod中的commands参数里。可以通过kubectl describe pod etcd-$NODENAME -n kube-system来查看(省略部分参数)
1 | Name: etcd-$NODENAME |
然而,如果您尝试编辑pod中的参数,会发现它们是不可修改的。
不过,如果您需要修改参数,还有另一个办法,通过修改/etc/kubernetes/manifests/下的yaml文件来修改运行中kubernetes集群中”系统”Pod的参数。原理是,当您把yaml文件修改后,kubelet会自动监听yaml文件的变更,并重新拉起本机器上的pod。
举个例子,如果您希望关闭etcd集群对客户端的认证,那么您可以修改/etc/kubernetes/mainfiest/etcd.yaml,将client-cert-auth设置为false,把trusted-ca-file去掉。注意:三台master机器节点都需要执行此操作
偶尔也回首一下处理的棘手问题吧。问题的现象是,通过kubernetes get node输出的ip不是期望的ip地址。大概如下所示
1 | ip addr |
最终输出的不是预期的ip1地址,而是ip2地址。
按藤摸瓜,kubernetes把节点信息保存在/registry/minions/$node-name中的InternalIp 字段。
InternalIp是如何确定的呢,这段代码位于pkg/kubelet/nodestatus/setters.go中
1 | // 1) Use nodeIP if set (and not "0.0.0.0"/"::") |
我们的场景下没有手动设置nodeIp,如需设置通过kubelet命令行即可设置 –node-ip=localhost,最终通过如下的go函数获取ip地址
1 | addrs, _ = net.LookupIP(node.Name) |
对这行go函数进行strace追溯,最终调用了c函数,getaddrinfo函数。getaddrinfo底层是发起了netlink请求,开启netlink的抓包
1 | modprobe nlmon |
通过抓包我看到通过netlink报文请求返回的ip地址顺序都是合乎预期的,只能是getaddrinfo函数修改了返回的顺序
Google了一下发现是getaddrinfo支持了rfc3484导致了ip的重新排序,代码地址glibc/sysdeps/posix/getaddrinfo.c
RFC3484 总共有十个规则,比较关键的有
1 | Rule 9: Use longest matching prefix. |
举个例子,假如机器的ip地址是 172.18.45.2/24,它会更青睐于172.18.45.6而不是172.31.80.8。这个RFC存在较大的争议,它与dns轮询策略不兼容,如:dns服务器轮询返回多个ip地址,客户端总是选择第一个ip连接。与这个策略存在很大的冲突。并且社区内也有投票试图停止对RFC3484 rule9的适配, 但是最终被拒绝了。
根据分析,认为是ip2的地址小于ip1的地址,最终glibc排序的时候把ip2放在了前面。最终我们给kubelet配置了eth0地址的–node-ip,解决了这个问题。
什么是umask, umask即user file-creation mask. 用来控制最终创建文件的权限。
umask是进程级属性,通常是由login shell设置,可以通过系统调用umask()或者命令umask permission来修改,通过umask命令来查询,linux内核版本4.7之后,还可以通过cat /proc/self/status|grep -i umask 查询,示例如下
1 | shoothzj:~/masktest $ umask |
一般来说,umask的系统默认值在**/etc/login.defs** 中设置
1 | shoothzj:~ $cat /etc/login.defs|grep -i umask |
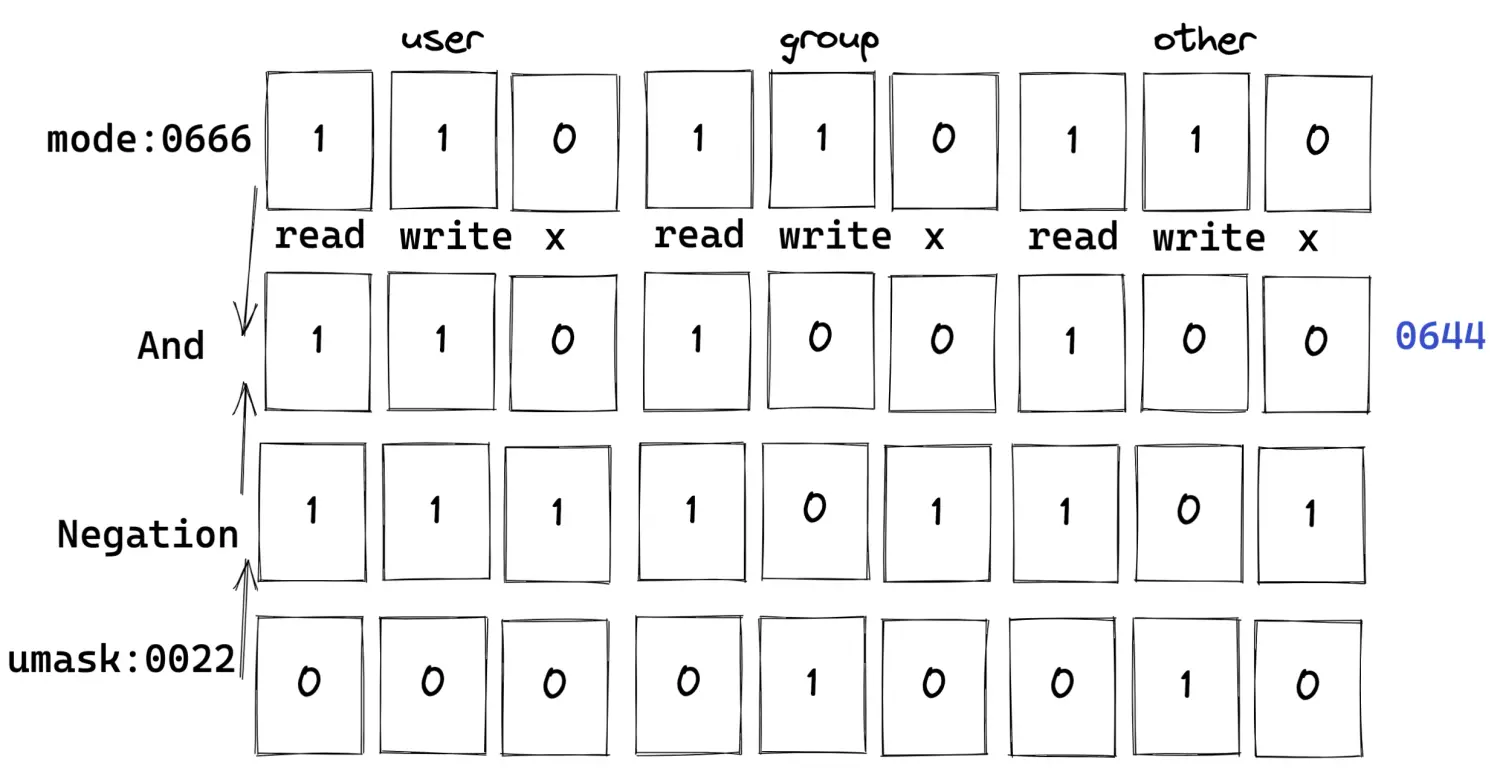
针对标准函数open来说,最终写入磁盘的权限位是由mode参数和用户的文件创建掩码(umask)执行按位与操作而得到。
假设当umask为0022时,创建一个具有0666权限的文件,就会进行运算决定文件的最终权限,先对掩码取非,再和指定的权限进行binary-And操作,如图所示
示例代码如下
1 |
|
结果如下,权限644,符合预期
1 | ll |